Python3反爬虫原理与绕过实战 第7.2节 浏览器特征属性检测对应的绕过方式 用pyppeteer将无头浏览器的JS属性做的和浏览器一样
Python3反爬虫原理与绕过实战 第7.2节里面提到了网站如何通过检测JS属性来判断是否为爬虫,但是只给出了结果图,并未给出对应的绕过方式,通过各种查资料,终于可以使用pyppeteer将无头浏览器的JS属性做的和浏览器一样了,记录下。
废话不多,直接上完整代码:
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(
{'headless': True,
'args': ['--no-sandbox',
'--disable-infobars',
'--window-size=1366,768',
'--lang=zh-CN',
# '--proxy-server={}'.format(get_ip()),
],
}
)
page = await browser.newPage()
# 设置页面视图大小
await page.setViewport(viewport={'width': 1366, 'height': 768})
await page.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36")
#设置JS属性
await page.evaluateOnNewDocument(
'''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
await page.evaluateOnNewDocument('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
await page.evaluateOnNewDocument(
'''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN', 'zh'] }); }''')
await page.evaluateOnNewDocument(
'''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5], }); }''')
await page.goto('http://www.porters.vip/features/browser.html')
await asyncio.sleep(1)
await page.screenshot({'path': 'example.png'})
await page.close()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
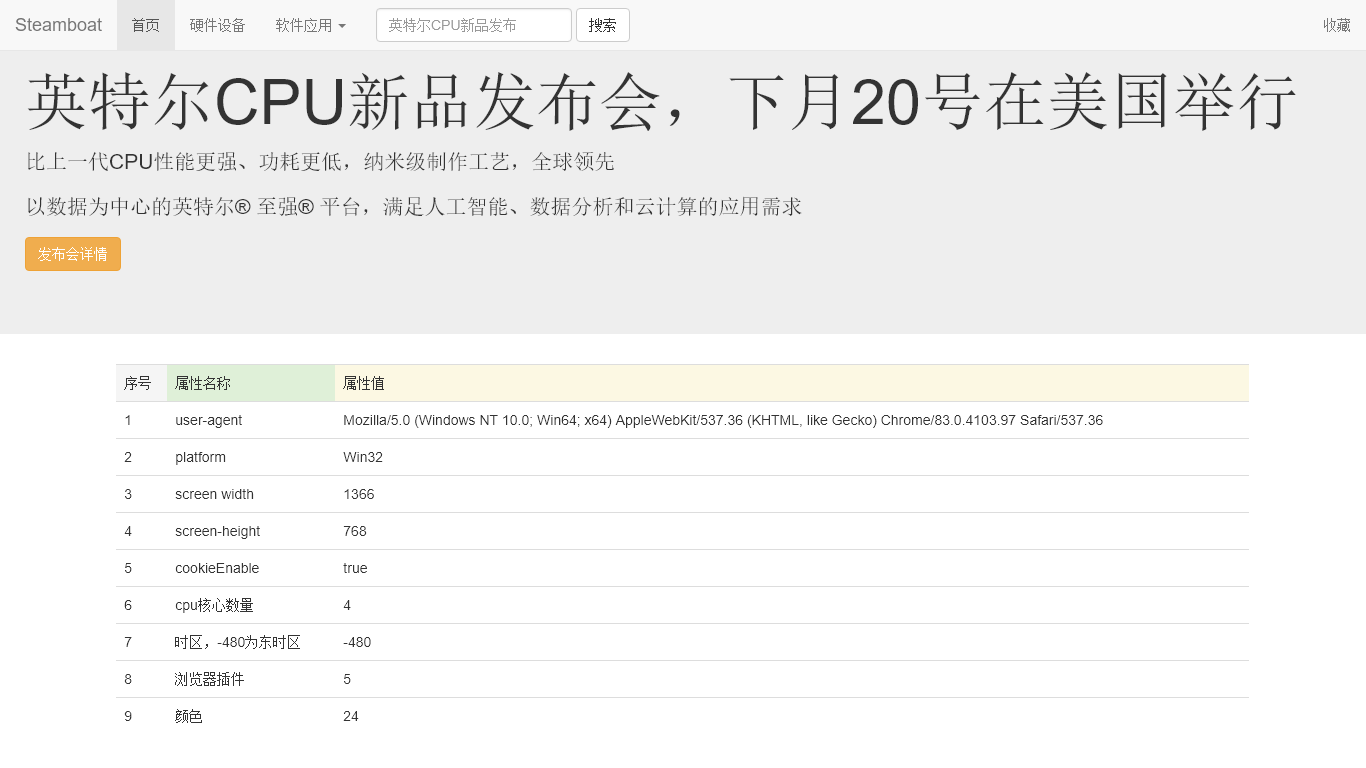
效果:
博文最后更新时间:
评论
-
暂无评论